

Dit is het originele opinie artikel wat ik enige tijd geleden aan KDNuggets gestuurd had, ik zal het in het kader van de Dataloog nog eens vertalen, maar omdat een kritisch tegengeluid tegen de deep learning hype nodig is, wilde ik deze toch graag online plaatsen.
Introduction
Data Science, and particularly its related machine learning discipline has brought the world astonishing results. We have seen machine learning developing from recognizing a cat on a picture to generating the next Rembrandt [1]. Recent advances on Deep Learning and Deep Generative Adversarial Networks are currently being used to developing new medicines for curing cancer [2]. All those results seemingly point a future where data driven scientific discoveries are the way forward [3]. While this may be appealing to data scientists, I believe that there are fundamental limitations of using solely data for solving problems [4].
In this blogpost I make an attempt to explain why Computational Science may matter more than Data Science in specific cases. I do this by first defining both fields of sciences while providing overlaps and differences. Next, I provide typical comments on the Data Science method, then point at specific limitations of Data Science. Finally, I come with three illustrations of cases in which Data Science may indeed reveal insights but Computational Science may.
Please note, this blogpost aims to emphasize the practical use and limitations of Data Science methods and not be a scientific plea for either method. There is an active discussion though on the third (computational science) [5], [6] and fourth (data science) [3] paradigm of science, their pros and cons [7], [8]. Next, it this post reflects my literature backed personal opinion. Let me state clearly, I do think Data Science matters, but in this blogpost advocate that data scientists should also look beyond their scope and be aware that for some data driven problems Computational Science may be a more suitable.
Data Science vs Computational Science
Before going into the limitations, we need to have a clear understanding of how we define both fields of science. These literature based definitions reflect what I think Data Science and Computational Science involve. In this blogpost I refer at Data Science as the Art of generating insight, knowledge and predictions by applying methods on datasets[9]. Next, I see Computational Science as the Art of developing validated (simulation) models in order to gain a better understanding of a system’s behavior[10]. This definition leaves out the part of Computational Science that involves computational complexity and high performance computing.
From these definitions is may be clear that there is a significant overlap between both sciences (see Fig1 below) [8]. In fact, data driven approach to modelling intertwines both fields of sciences [11]. Yet, the differences can be found in the focus of both: Computational sciences focuses on development of causal models rather than extracting patterns or knowledge from data by statistical models, while this is what Data Science is all about.

Figure 1 left adapted [12] from right adapted from [13]
Limitations of data science as predictive analytics
There are several limitations of the Data Science approach to problem solving mentioned that have been addressed [5]. In data science, we do not aim to understand the system, even if we are able to make predictions from the data that the system generates. The question is, is this needed? Moreover, an often heard comment on the use of machine learning is that we do not really understand the insides of this piece of machinery. Again the question is, is this really a bad thing?
This point taken, do we need to understand the dynamics of a system to be able to make predictions of future states of a system? Maybe this is valid as long as the data scientist is able to distinguish the spurious correlations from the real correlations [14]. But this requires at least implicit treatment of the results of any Data Science model in line with the domain knowledge of the data scientist. On a more abstract level this implies that data scientists at lease use a mental model of how a system would behave. Making this explicit during Data Science projects may increase correctness and reproducibility [15].
But Perhaps most important, by definition data contains limited information on the behavior in the system, since data is result of what is measured and thus an aggregation of the dynamics that result in this data. We should therefore wonder what dynamics are beyond the measured results[6].
For example, is we research customer retention by gathering contract data, the individual decision process of a customer that results in a decision is not measured. If we would be able to measure HOW customers make decisions by stated preferences, we may exclude other factors such as gut feeling. There is always a deeper level underneath the data that is not part of what is measured.
Now, from this idea of dynamics underlying the data we immediately see that if these dynamics change, then the data will change as well. As such, Data Science based predictions work only if the future is fundamentally like the past [5], and even this is the case then only valid within range [4]. Typically, many systems in which behavior plays role contain tipping points and regime changes in which the dynamics that generate the data fundamentally change as well. We call these system complex systems in which the complexity lies in the inability to predict future states of the system based on knowledge of its current state [16], [17], .
In the next section I will provide several illustrations of what insight Data Science may reveal in these systems and how Computational Science extends these insights.
Illustration 1 – Extending the dynamics of transactional data
Let the system be a system of supply and demand which resources are transferred from the supply side to the demand side. For example, a shop and customers, ships and havens, predator pray systems in ecology. Typically in these systems the data contains transactions between both sides of the system. As an example, the receipt of a transaction is typically a piece information available.
Data science could help to forecast demand based on historical patterns, generate user profiles based on clustering methods and numerous other things. Yet, there is a limitation in the data, since it measures transactions, which are successful results of the supply and demand side interaction. Using solely the set of transactions for leaves out unsuccessful transactions, such as out of stock products , customers unable to reach a shop, or unsuccessful hunt for preys by predators. Building an simulation model that generates simulated behavior allows us to probe the system in different ways and analyze scenarios not present in the data. More important, It makes the unsuccessful transactions measurable. As such, a simulation model literally extends the data!
Illustration 2 – Cascading failures in complex system
Let the system at hand be a connected system typically acting as a network of nodes, for example an electricity network, social or human network or a soccer team. Now, let de data gathered by (1) properties of each node such as power capacity in an electricity network or soccer player properties and (2) the activity of the system, e.g. electricity flow between nodes or player activity.
The Data Science methods could help to predict future activities, correlate node properties with activities, or compare nodes types (e.g. soccer player types). But what would happen if an electricity hub fails or a player gets a red card? Or how does a virus such as Ebola spread though human networks, (see Figure 2)? The concept of how failures or information in a system affect other elements (cascade) is typically part of Computational Science [16]. Computational models have shown to reveal the cascading behavior in networks by modelling the mechanisms present in the system [16], [17]. From these mechanisms, future cascades can be predicted, or better advices for improvement of network stability can be made. In this sense simulation models allow to take a different perspective on the system than the data provides.
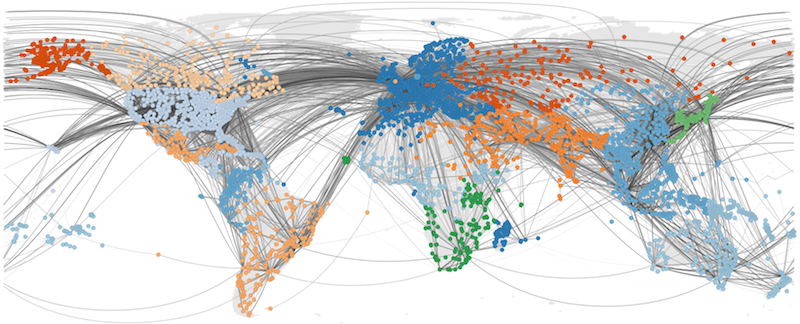
Figure 2 spread of Ebola from [18]
Illustration 3- Tipping points in system configurations
Let’s consider a system in which a medium flows through a space, for example blood flow through veins or a crowd entering a stadium. Typically in these systems we see regime changes in the behavior of the system. For instance, the change from laminar to turbulent (chaotic) flow or the sudden emergence of panic in a crowd after a tipping point has been reached. Typically, there are early warning signals in the system that announce an upcoming tipping point in the future. In many cases we want to avoid the regime change and as such intervene in the system before the tipping point has been reached.
Information present on these systems often contain data on location, movement or state of element in the system. The problem to solve is often to predict a future state of the system given the data on its current state. If the future state is in the same regime this may be possible with typical Data Science methods. Next, Data Science may reveal insight in future movements or local densities or correlate densities with tipping points from past data. Yet, It does not help us to understand how and why these tipping points occur. For this we need modelling.
Moreover, prediction of behavior in a chaotic system may not be feasible with machine learning tools, and only very recently first result have shown to do a model free prediction of a chaotic system [19]. While these results have been identified as very promising, it may take a while before data scientists are able to use these results in typical Data Science projects. Until that time, be aware of computational models.
Conclusions and solutions
In this blogpost I have shown how Computational Science could extend the field of Data Science in specific cases. For Data Scientists working in the practical field I would recommend the following advices:
- As a data scientist be aware that data is generated from underlying dynamics that may be more interesting than the data itself. Be explicit in your mental model on how these dynamics lead to the data you gathered.
- Question yourself whether the project goal is within the boundaries of system configuration that generated the data. If so, be aware of spurious correlation and beign to far outside the data’s domain, if not, make a model.
- For recruiters, it may be good to know that Computational scientists may use Data Science methods but the other way around is not often seen. It may be beneficial to add computational scientists to a data science team.
- And, keep track no new developments of deep learning on chaotic systems, these are promising. But until these models are commonly used, keep computational scientists around you.
[1] “The Next Rembrandt.” [Online]. Available: https://www.nextrembrandt.com/. [Accessed: 24-May-2018].
[2] A. Kadurin et al., “The cornucopia of meaningful leads: Applying deep adversarial autoencoders for new molecule development in oncology,” Oncotarget, vol. 8, no. 7, pp. 10883–10890, Feb. 2017.
[3] A. J. G. Hey, The fourth paradigm : data-intensive scientific discovery. .
[4] L. R. Varshney, “Fundamental Limits of Data Analytics in Sociotechnical Systems,” Front. ICT, vol. 3, no. 2, pp. 1–7, 2016.
[5] P. J. Haas, P. P. Maglio, P. G. Selinger, and W.-C. Tan, “Data is Dead… Without What-If Models.”
[6] P. Sloot, “Big Nonsense; the end of scientific thinking.” p. 86, 2016.
[7] G. Bell, T. Hey, and A. Szalay, “Computer science. Beyond the data deluge.,” Science, vol. 323, no. 5919, pp. 1297–8, Mar. 2009.
[8] “Data Science: What is It and How is It Taught?” [Online]. Available: https://sinews.siam.org/Details-Page/data-science-what-is-it-and-how-is-it-taught. [Accessed: 26-May-2018].
[9] D. Donoho, “50 Years of Data Science,” J. Comput. Graph. Stat., vol. 26, no. 4, pp. 745–766, Oct. 2017.
[10] U. Rüde et al., “Future directions in CSE education and research,” 2015.
[11] “ICCS – International Conference on Computational Science.” [Online]. Available: https://www.iccs-meeting.org/iccs2018/. [Accessed: 26-May-2018].
[12] M. R. ( Spruit and M. J. . Brinkhuis, “Applied Data Science – Software Systems – Utrecht University.” [Online]. Available: https://www.uu.nl/en/research/software-systems/organization-and-information/labs/applied-data-science. [Accessed: 01-Jun-2018].
[13] “Master Programme in Computational Science,” 2013.
[14] T. Vigen, “Spurious Correlations.” [Online]. Available: http://www.tylervigen.com/spurious-correlations. [Accessed: 24-May-2018].
[15] J. M. Epstein, “Why Model?,” Oct. 2008.
[16] J. Borge-Holthoefer, R. A. Banos, S. Gonzalez-Bailon, and Y. Moreno, “Cascading behaviour in complex socio-technical networks,” J. Complex Networks, vol. 1, no. 1, pp. 3–24, Jun. 2013.
[17] I. Dobson, B. A. Carreras, V. E. Lynch, and D. E. Newman, “Complex systems analysis of series of blackouts: Cascading failure, critical points, and self-organization,” Chaos An Interdiscip. J. Nonlinear Sci., vol. 17, no. 2, p. 026103, Jun. 2007.
[18] D. Brockman, L. Schaade, and L. Verbeek, “Ebola,” 2014. [Online]. Available: http://rocs.hu-berlin.de/publications/ebola/index.html. [Accessed: 01-Jun-2018].
[19] J. Pathak, B. Hunt, M. Girvan, Z. Lu, and E. Ott, “Model-Free Prediction of Large Spatiotemporally Chaotic Systems from Data: A Reservoir Computing Approach,” Phys. Rev. Lett., vol. 120, no. 2, p. 024102, Jan. 2018.
[2] A. Kadurin et al., “The cornucopia of meaningful leads: Applying deep adversarial autoencoders for new molecule development in oncology,” Oncotarget, vol. 8, no. 7, pp. 10883–10890, Feb. 2017.
[3] A. J. G. Hey, The fourth paradigm : data-intensive scientific discovery. .
[4] L. R. Varshney, “Fundamental Limits of Data Analytics in Sociotechnical Systems,” Front. ICT, vol. 3, no. 2, pp. 1–7, 2016.
[5] P. J. Haas, P. P. Maglio, P. G. Selinger, and W.-C. Tan, “Data is Dead… Without What-If Models.”
[6] P. Sloot, “Big Nonsense; the end of scientific thinking.” p. 86, 2016.
[7] G. Bell, T. Hey, and A. Szalay, “Computer science. Beyond the data deluge.,” Science, vol. 323, no. 5919, pp. 1297–8, Mar. 2009.
[8] “Data Science: What is It and How is It Taught?” [Online]. Available: https://sinews.siam.org/Details-Page/data-science-what-is-it-and-how-is-it-taught. [Accessed: 26-May-2018].
[9] D. Donoho, “50 Years of Data Science,” J. Comput. Graph. Stat., vol. 26, no. 4, pp. 745–766, Oct. 2017.
[10] U. Rüde et al., “Future directions in CSE education and research,” 2015.
[11] “ICCS – International Conference on Computational Science.” [Online]. Available: https://www.iccs-meeting.org/iccs2018/. [Accessed: 26-May-2018].
[12] T. Vigen, “Spurious Correlations.” [Online]. Available: http://www.tylervigen.com/spurious-correlations. [Accessed: 24-May-2018].
[13] J. M. Epstein, “Why Model?,” Oct. 2008.
[14] J. Borge-Holthoefer, R. A. Banos, S. Gonzalez-Bailon, and Y. Moreno, “Cascading behaviour in complex socio-technical networks,” J. Complex Networks, vol. 1, no. 1, pp. 3–24, Jun. 2013.
[15] I. Dobson, B. A. Carreras, V. E. Lynch, and D. E. Newman, “Complex systems analysis of series of blackouts: Cascading failure, critical points, and self-organization,” Chaos An Interdiscip. J. Nonlinear Sci., vol. 17, no. 2, p. 026103, Jun. 2007.
[16] J. Pathak, B. Hunt, M. Girvan, Z. Lu, and E. Ott, “Model-Free Prediction of Large Spatiotemporally Chaotic Systems from Data: A Reservoir Computing Approach,” Phys. Rev. Lett., vol. 120, no. 2, p. 024102, Jan. 2018.












